✱ Bulletins
What, if anything, can or should one make of Rick Rubin appearing in a Polymarket commercial?

I cannot begin to tell you how wildly, how passionately, how insanely unready my APIs are for agentic AI.
One of the sick things about gen AI companies is not only did they steal my shit (and yours), but that the cost of refusing to be complicit by using their products is ultimately unrealistic for anyone to bear. So you pay $20/mo or watch an ad to get your piece from what was stolen from all of us.
what… is this? why is this the timeline that we’re in?

Playing today. Forgotten Pleasures (2017) by Findlay.
What genre is this? Pop/rock/ambient-electronica? Whatever it is, it’s good. A little noisy, a little gritty. Intimately angry.
It’s the year 2150. ConsciousnessCopy’s Plus tier now supports up to 3500 organic memories (1000 episodic, 2500 semantic) and 50k generative memories. I’m waiting for my girlfriend to return from her cortical scraping appointment so she can remind me where we decided to send our Simojis (simulation emojis) on virtual holiday. I know it’s in our chats somewhere but I just can’t find it because Apple still won’t let me search inside a single Messages thread. My contact lenses have ads now.
One of the consequences of generative model slop sloshing around the internet is that it’s not nearly as easy as it used to be to find an actually good reference link to include in a piece of writing. Blog posts and technical pages from websites that look like they will be around long enough to be worth linking to are pages behind absolute dogshit.
Who do you blame? The people working at the companies making the tools, or the losers whose idea of passive income hustle/infinite money glitch is to vibe code a bunch of ad-filled websites populated with generated content, and may the loser with the best SEO game win?
I blame both. And I also blame us, because none of this would be popping if we weren’t, in the main, feeding or benefitting from it. All of us with 401ks and index fund investments own a part of this, by the very textbook definition of “own”.
I eagerly await the appointment of a Blue-ribbon commission to investigate the events leading up to the script of Slow Horses season five, identify those responsible, and bring them swift American justice.

The whole point of art is to make you think about the human experience. The human condition. The human.

Playing today: ARCHE (2014) by DIR EN GREY.
Japanese heavy/melodic metal band: DIR EN GREY. A friend introduced me to UROBOROS (2008) over a decade ago and I’ve been into the band ever since. ARCHE is less cacophonous, just as heavy, just as guttural, just as emotional. A no-skips album for me.
🎵

On deck today: nimrod. by Green Day (1997)
I’d say it’s an underrated album, but I think it was underrated only by me. Very fun.
🎵
Avril Lavigne’s “Complicated” is a 10/10 song.
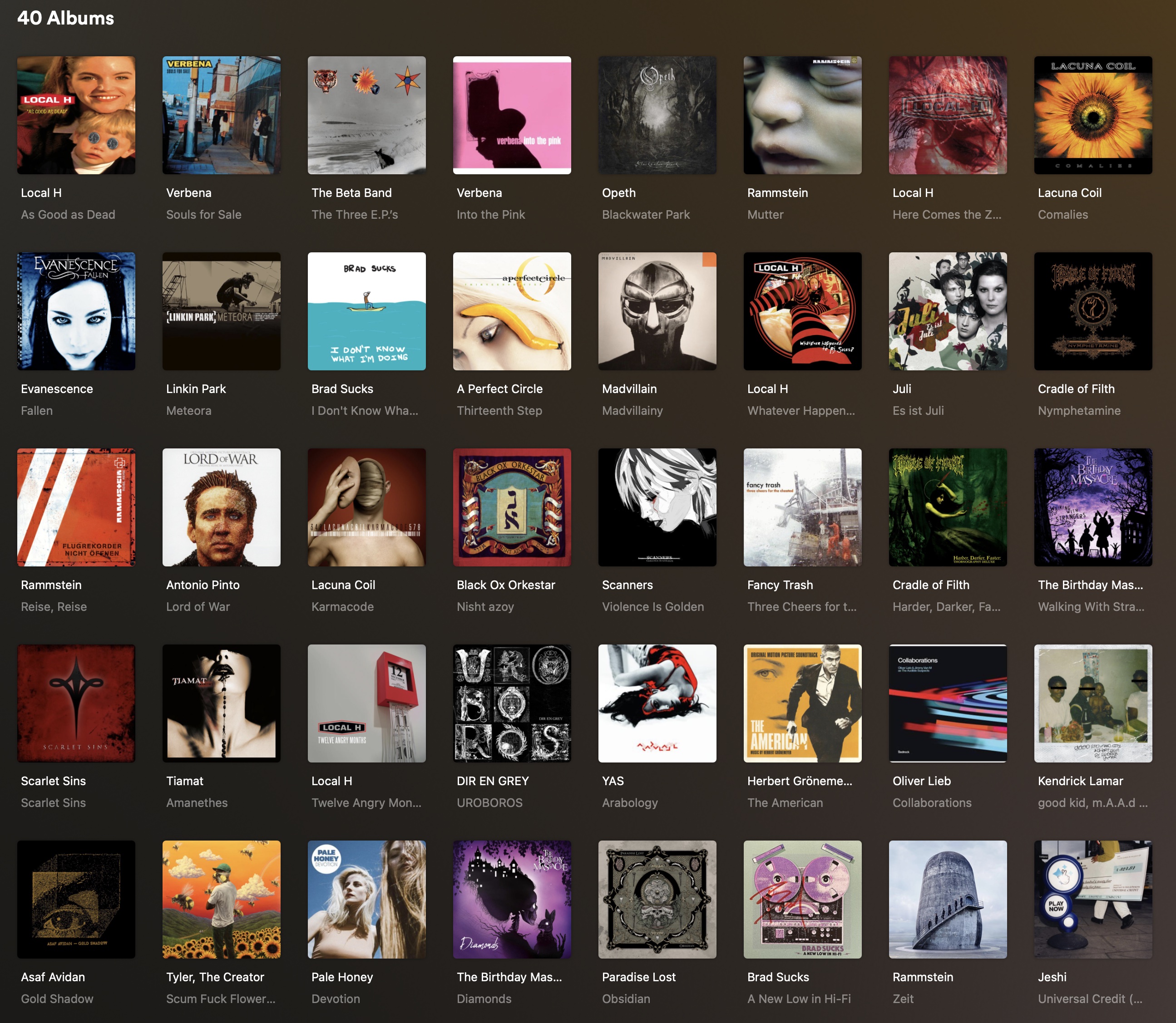
Favorite albums of all time. 40 out of thousands.
It is wildly unrealistic to expect significant decision makers in a publicly traded company to put morality or ethics over the bottom line.
I don’t know if that’s too cynical or too obvious, but it’s an axiom I live by in 2025.